Preston Lau: A Journey Through Memories, Tech, and Humanity
Welcome to my personal blog that delves into the intricate tapestry of personal albums and the fascinating intersection of ever-evolving technology and humanity. Come along on a journey with me as we delve into the seamless fusion of creativity, state-of-the-art AI and robotics, intricately interwoven within the tapestry of our shared awareness. Have fun!
DrEureka LLMs Sim-to-Real Transfer Robot Balance and Walk on a Yoga Ball
AI Summary
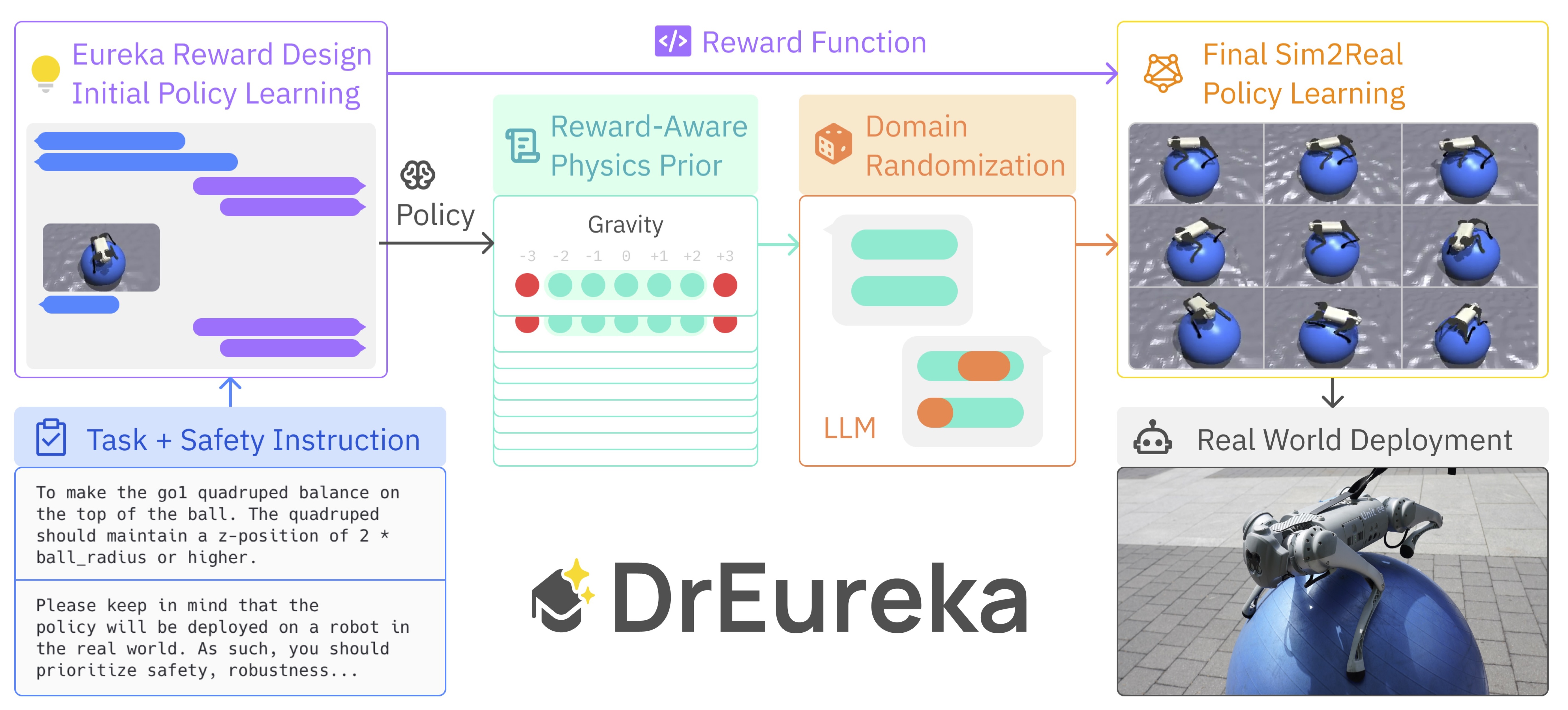
DrEureka is an LLM-guided sim-to-real approach for efficiently acquiring robot skills at scale by automating the design and tuning of task reward functions and simulation physics parameters. It requires only physics simulation, eliminating manual design's need for labor and time, and outperforms human-designed approaches on quadruped locomotion, dexterous manipulation, and a novel "walking globe" task.
In the field of robotics, transferring policies learned in simulation to the real world (sim-to-real) has emerged as a promising approach for efficiently acquiring robot skills at scale. However, the sim-to-real process typically involves manual design and tuning of task reward functions and simulation physics parameters, making it time-consuming and labor-intensive. A recent project called DrEureka aims to automate and accelerate this process by leveraging the power of Large Language Models (LLMs).
How DrEureka Works
DrEureka is an LLM-guided sim-to-real approach that requires only the physics simulation for the target task. It automatically constructs suitable reward functions and domain randomization distributions to support real-world transfer, eliminating the need for iterative manual design. The process can be broken down into three key steps:
An LLM synthesizes reward functions based on the task and safety instructions, along with the environment source code.
An initial policy is rolled out in perturbed simulations to create a reward-aware physics prior, which provides a suitable sampling range for physics parameters.
The LLM generates valid domain randomization configurations using the reward-aware prior as context. These are used to re-train policies for real-world deployment.
Impressive Real-World Performance
Researchers have evaluated DrEureka on quadruped locomotion and dexterous manipulation tasks, demonstrating its generality and applicability to diverse robots and tasks. The results are impressive:
On quadruped locomotion, DrEureka-trained policies outperformed those trained with human-designed reward functions and domain randomization parameters by 34% in forward velocity and 20% in distance traveled across various real-world terrains.
In dexterous manipulation, DrEureka's best policy performed nearly 300% more in-hand cube rotations than the human-developed policy within a fixed time period.
On the novel and challenging "walking globe" task, where a quadruped attempts to balance and walk on a yoga ball, the DrEureka-trained policy maintained balance for minutes on diverse indoor and outdoor terrains with minimal safety support.
The Future of Sim-to-Real with LLMs
DrEureka represents a significant step forward in automating sim-to-real transfer for robotics. By leveraging the world knowledge and hypothesis generation capabilities of LLMs, it can efficiently search the vast space of reward functions and domain randomization parameters to find effective configurations.
As LLMs continue to advance, we can expect further improvements in their ability to reason about physics and optimize complex problems. This could lead to even more powerful and efficient sim-to-real pipelines, accelerating the development of robust, real-world robot skills.
While there is still room for improvement (see video below of one failed case, more videos in the project page), such as incorporating real-world execution feedback and additional sensors, DrEureka demonstrates the immense potential of combining LLMs with physics simulations for robot learning. As this approach matures, it could revolutionize the way we develop and deploy robots, making the process faster, more efficient, and more accessible than ever before.