Preston Lau: A Journey Through Memories, Tech, and Humanity
Welcome to my personal blog that delves into the intricate tapestry of personal albums and the fascinating intersection of ever-evolving technology and humanity. Come along on a journey with me as we delve into the seamless fusion of creativity, state-of-the-art AI and robotics, intricately interwoven within the tapestry of our shared awareness. Have fun!
Reality Check: Mistral OCR vs. Gemini Flash 2.0 - The 43% Accuracy Gap
AI Summary
Mistral OCR's 94.89% accuracy surpasses industry leaders like Google Document AI (83.42%) and Azure OCR (89.52%), but performs poorly on certain documents, including financial and medical forms, with lower accuracy rates of 80.1% and 45.3%, respectively.
Throughout human history, our greatest leaps forward have been tied to how we store and access information. From ancient hieroglyphs carved in stone to the revolutionary printing press, each advancement has made knowledge more accessible and actionable.
Yet today, despite our digital revolution, we face a surprising bottleneck: approximately 90% of the world's organizational data remains locked away in documents. These documents—whether PDFs, scanned papers, or image files—represent a vast ocean of untapped intelligence that until now has been difficult for machines to truly comprehend.
Introducing Mistral OCR: Beyond Simple Text Recognition
Mistral has announced the release of Mistral OCR — a multilingual, advanced optical character recognition (OCR) API that allows users to accurately convert any PDF to a text or markdown file. Unlike traditional OCR (Optical Character Recognition) systems that simply convert images of text into machine-encoded text, Mistral OCR comprehends documents in their entirety.
In Mistral's own words: "Unlike other models, Mistral OCR comprehends each element of documents—media, text, tables, equations—with unprecedented accuracy and cognition. It takes images and PDFs as input and extracts content in an ordered interleaved text and images."
What sets Mistral OCR apart is its ability to understand every element within a document:
Text in multiple languages and scripts
Complex tables and their relationships
Mathematical equations and scientific notation
Images, charts, and graphs
Advanced layouts including LaTeX formatting
The result is a system that doesn't just see text—it understands context, meaning, and the relationships between different elements on a page. The text and markdown output allows PDFs to be readily ingested in downstream applications for further automated processing, solving a persistent challenge in the industry.
Mistral OCR Internal Benchmarks
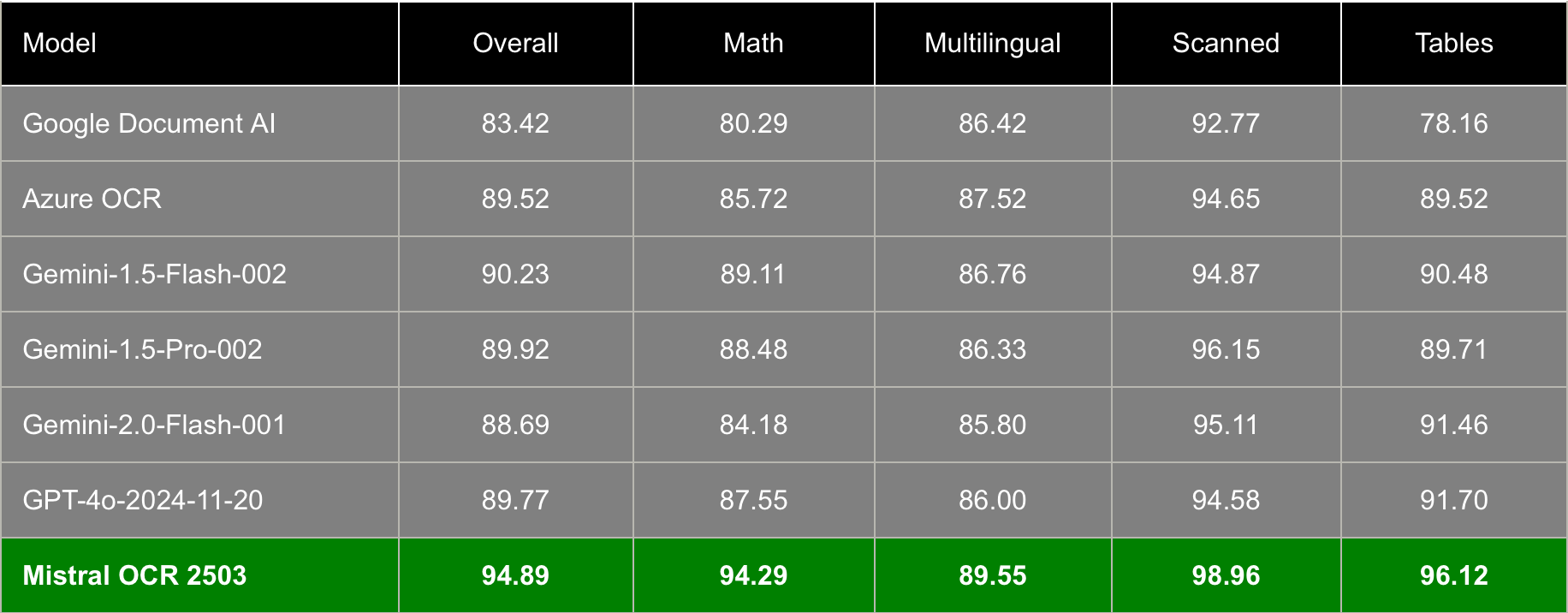
In rigorous benchmark tests, it consistently outperforms industry leaders. Overall accuracy reaches 94.89%, significantly higher than competitors like Google Document AI (83.42%), Azure OCR (89.52%), and even cutting-edge models like GPT-4o (89.77%) and Gemini 2.0 (88.69%).
Where Mistral OCR truly shines is in specialized content:
Mathematical content: 94.29% accuracy
Table recognition: 96.12% accuracy
Scanned document handling: 98.96% accuracy
For organizations that operate globally, the multilingual capabilities are particularly noteworthy. Mistral OCR achieves over 99% accuracy in languages like Russian, French, German, Spanish, and Ukrainian, with strong performance even in complex scripts like Hindi (97.55%) and Chinese (97.11%).
The company states that the tool is able to "parse, understand, and transcribe scripts, fonts, and languages across all continents," being natively multilingual and multimodal. Independent testing has even shown promising results with languages not officially listed in Mistral's benchmarks, such as Thai, where one user reported, "It displays Thai characters in Unicode [in JSON]. It's done a pretty good job with the Thai characters and being able to OCR them."
While Mistral's internal benchmarks show their OCR solution outperforming competitors like Gemini 2.0 Flash (94.89% vs. 88.69% overall accuracy), independent testing by document processing experts tells a more complex story.
Reducto, a provider of AI document ingestion solutions, conducted their own evaluation comparing Mistral OCR and Gemini 2.0 Flash on real-world document types. Their findings differ significantly from Mistral's published benchmarks.
In Financial Document Test Case: When processing a brokerage research report with dense tables, Gemini 2.0 Flash captured all content with only minor structural errors. A reader would not miss any information. In contrast, Mistral OCR exhibited several critical issues:
Dropping header and footer information
Incorrectly classifying the first table as an image then repeating it with incorrect headers
Adding hallucinated data in a second column to the first table
Misreading text (e.g., "JZP-110 Sales" as "I2P-110 Sales")
In Medical Form Test Case: On a military medical incident report with handwritten elements, Gemini extracted information perfectly. Mistral OCR showed several problems:
Incorrectly marking checked boxes as unchecked
Dropping headers and footers
Making table structure mistakes that altered document meaning (e.g., incorrectly labeling medications)
Most notably, when tested on Reducto's comprehensive RD-FormsBench dataset (containing 1,000 diverse documents with handwriting, multiple languages, checkboxes, and complex layouts), the performance gap was substantial:
Gemini 2.0 Flash: 80.1% accuracy
Mistral OCR: 45.3% accuracy
This 43.4% accuracy difference raises questions about Mistral's internal benchmarking methodology. Reducto noted that their significantly lower results for Mistral stemmed from the model frequently marking large sections as images and returning cropped images without OCR data on complex documents.
Flexible Implementation: API-First with Self-Hosting Options
Mistral OCR is available today through the developer suite la Plateforme with an API endpoint (mistral-ocr-latest). Cloud and on-premises deployment options are also available, with self-hosting solutions offered selectively for organizations dealing with sensitive or classified information. The API accepts images and PDFs as input and provides extracted content with both text and images preserved in their original context and order.
Early adopters are already finding innovative ways to leverage this technology:
Scientific Research Acceleration: Research institutions are converting vast libraries of scientific papers into AI-ready formats, making them accessible to downstream intelligence engines. This is measurably speeding up collaboration and accelerating scientific workflows by turning static papers into active, queryable knowledge.
Cultural Heritage Preservation: Organizations responsible for historical archives are digitizing fragile documents, not just to preserve them but to make their contents accessible and searchable for future generations.
Customer Service Enhancement: Support teams are transforming mountains of product documentation and manuals into indexed knowledge bases, dramatically reducing response times and improving customer satisfaction.
Cross-Industry Knowledge Activation: From engineering drawings to lecture notes, from presentations to regulatory filings—Mistral OCR is helping organizations convert technical literature across design, education, legal, and other fields into formats that unlock intelligence and productivity.
Perhaps most exciting is Mistral OCR's ability to use documents as prompts, enabling precise instructions for information extraction. This capability allows users to pull specific data from documents and format it in structured outputs like JSON, which can then flow into downstream function calls or power intelligent agents.
This transforms passive documents into active resources that can trigger workflows, supply data to automated systems, or feed directly into analytical processes.
The Industry Reacts: Mixed Reviews from OCR Experts
Following Mistral's bold announcement of creating the "world's best document understanding API," industry experts have been quick to put the technology to the test with mixed results.
Kushal Byatnal, CEO of document processing platform Extend, offered a more measured perspective: "There is still a large gap for businesses in going from raw OCR outputs to document processing for mission-critical use cases. […] Anyone who goes in expecting 100% automation is in for a surprise."
He added a note of caution about implementation: "You still need to build and label datasets, orchestrate pipelines, detect uncertainty, and correct with human-in-the-loop, fine-tune, and a lot more. You can certainly get close to full automation over time, but it's going to take time and effort. But the future is on the horizon!"
Raunak Chowdhuri from Reducto, compared Mistral OCR and Gemini Flash 2.0, stating that "on financial documents, we find it drops content and hallucinates [on] complex tables. On healthcare forms, we found it misses basic checkbox detection and fails to correct table structure." His testing concluded that "Mistral is 43.5% less accurate when examining downstream LLM accuracy on complex parsed forms."
While Mistral OCR represents a significant step forward in document understanding technology, the conflicting benchmark results and independent testing suggest that claims of "PDF parsing being solved" may be premature. As Reducto concluded in their analysis:
Document processing isn't solved yet, but we're very excited by the improvements across the industry, and are optimistic about the potential for vision models to redefine the state of the art.