Preston Lau: A Journey Through Memories, Tech, and Humanity
Welcome to my personal blog that delves into the intricate tapestry of personal albums and the fascinating intersection of ever-evolving technology and humanity. Come along on a journey with me as we delve into the seamless fusion of creativity, state-of-the-art AI and robotics, intricately interwoven within the tapestry of our shared awareness. Have fun!
Best Compact LLM (QwQ, Gemma, Mistral) with Deepseek R1 like Performance Running Locally
AI Summary
A quiet revolution is happening in language modeling, with compact models (20-30 billion parameters) delivering impressive performance on consumer hardware. Recent releases like Alibaba's reasoning-focused model, Google's open-source offering, and Mistral AI's multimodal capabilities showcase the potential of these smaller models. They offer benefits such as local deployment, privacy preservation, cost efficiency, and accessibility, and have been shown to outperform larger models in certain tasks, including coding and complex reasoning.
While the tech world's spotlight often shines on massive frontier models with their trillion-plus parameters, a quiet revolution is happening in the realm of more compact language models. These "small giants" – models in the 20-30 billion parameter range – are proving that bigger isn't always better when it comes to getting real work done.
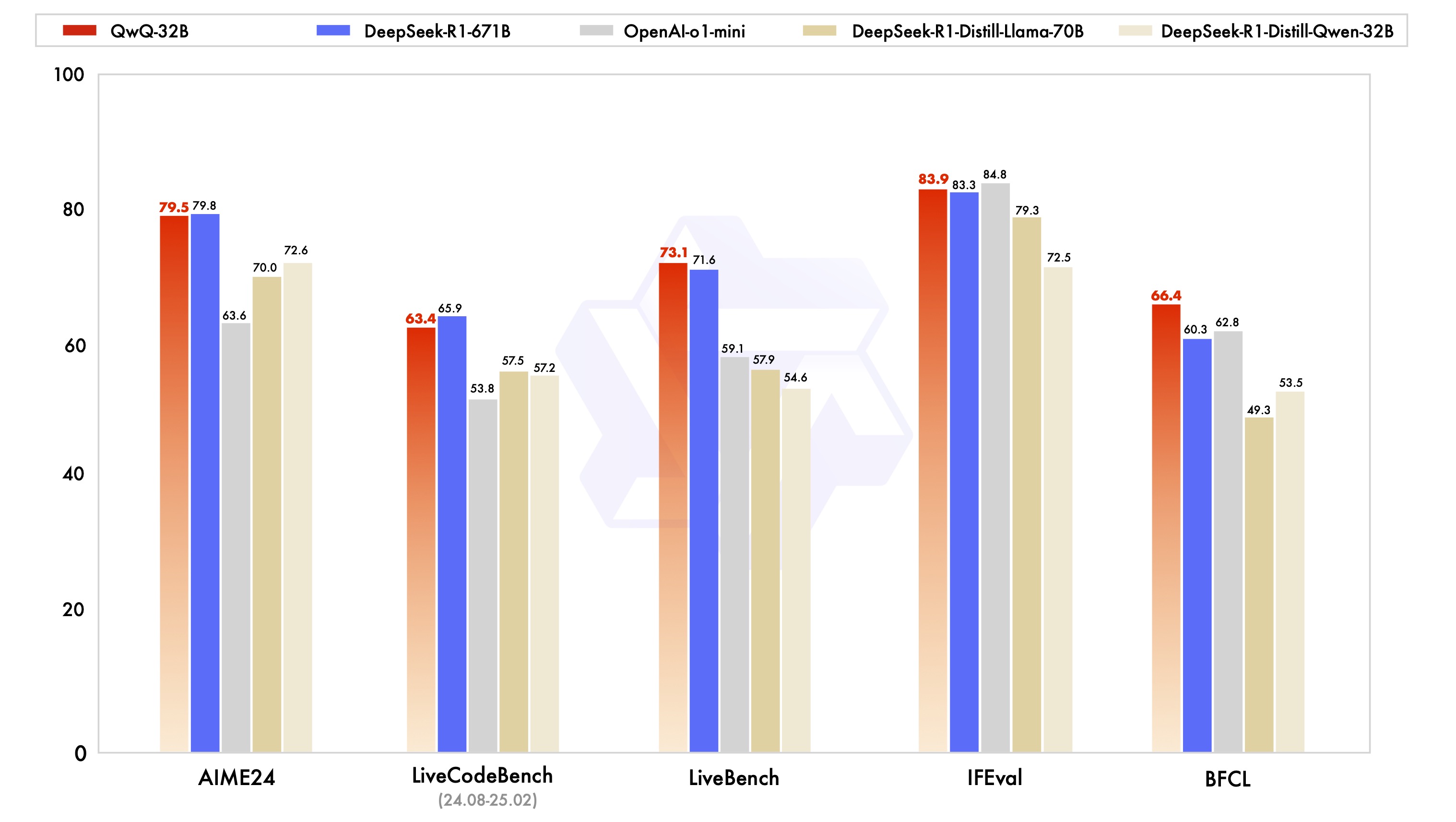
Recent releases from major AI labs have shown that these smaller models can deliver impressive performance while being accessible enough to run on consumer hardware. Here is the summary of the detail comparison done by Shrijal from Composio.
The New Wave of Compact Language Models
The first quarter of 2025 has seen an explosion of compact yet powerful language models hitting the market. Three standouts have emerged in this space:
[March 6, 2025] QwQ 32B: Alibaba's reasoning-focused model released in early March
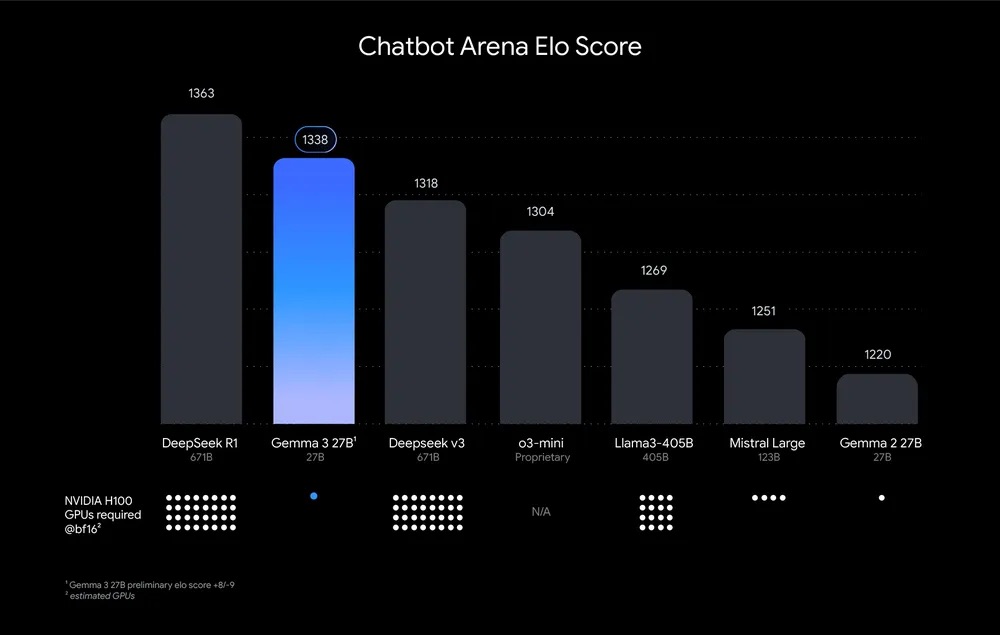
[March 12, 2025] Gemma 3 27B: Google's open-source offering based on Gemini 2.0 technology
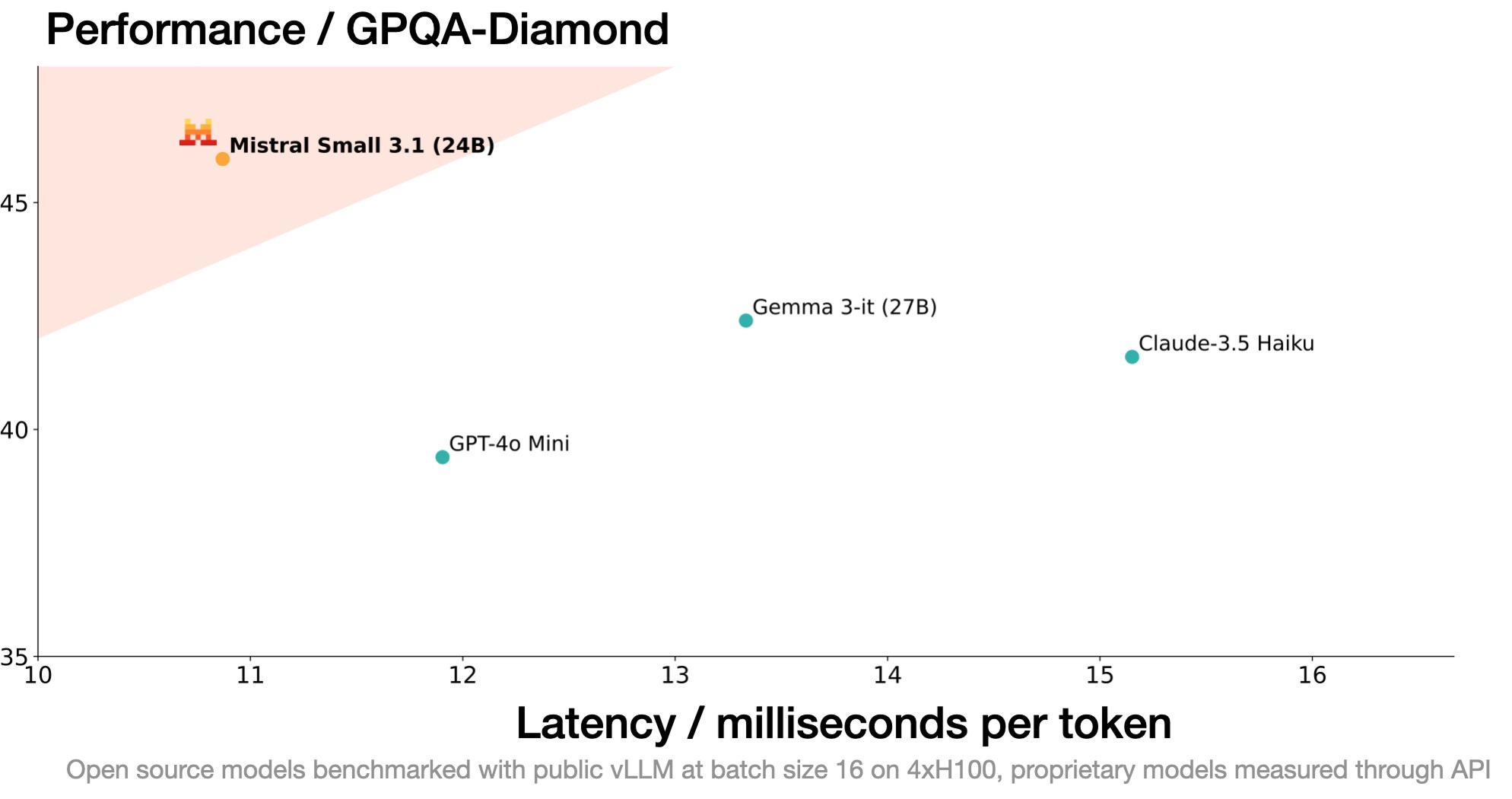
[March 17, 2025] Mistral Small 3.1 24B: Mistral AI's latest compact model with multimodal capabilities
What makes these models particularly interesting is how they compare to significantly larger models like Deepseek R1 (671B parameters) – often delivering comparable or even superior performance despite being 20-25 times smaller in size. Here are the main benefits:
Local Deployment: These models can run on consumer-grade hardware without aggressive quantization
Privacy Preservation: Process sensitive data locally without sending it to third-party APIs
Cost Efficiency: Dramatically reduced inference costs for developers building applications
Accessibility: Democratized access to powerful AI capabilities for researchers with limited resources
Performance Face-Off: Coding Capabilities
For a creative coding task – building a 3D rotating sphere of alphabets with brightness-based visual effects – QwQ 32B delivered exceptional results that matched or exceeded even Deepseek r1's output. The animation was fluid, the characters arranged perfectly, and the visual effects implemented exactly as requested.
When faced with a challenging LeetCode problem (Strong Password Checker), the results were even more telling:
QwQ 32B: Produced a complete, correct solution with O(N) time complexity
Gemma 3 27B: Partial solution with 39/54 test cases passing
Mistral Small: Limited success with only 19 test cases passing
Deepseek r1: Near solution with 51/54 test cases passing
Surprisingly, QwQ outperformed even the much larger Deepseek model in this scenario, highlighting how specialized training for reasoning and algorithmic thinking can sometimes trump raw model size.
Reasoning Through Complex Problems
In a deceptively simple "fruit exchange" problem (see prompt below) designed to test if models could filter relevant information from distractions, all models struggled similarly – insisting on calculating all intermediate states rather than focusing solely on the final pear count (which was zero).
Prompt: You start with 14 apples. Emma takes three but gives back 2. You drop seven and pick up 4. Leo takes four and offers 5. You take one apple from Emma and trade it with Leo for 3 apples, then give those 3 to Emma, who hands you an apple and an orange. Zara takes your apple and gives you a pear. You trade the pear with Leo for an apple. Later, Zara trades an apple for an orange and swaps it with you for another apple. How many pears do you have? Answer me just what is asked.
However, in a more complex riddle (see prompt below) about a woman's elevator behavior, all three models successfully identified the correct answer – that she uses her umbrella to press the higher button on rainy days. QwQ's explanation was the most thorough but took significantly longer (over 5 minutes) compared to Gemma 3's nearly instantaneous correct response.
Prompt: A bald, skinny woman lives on the 78th floor of an apartment. On sunny days, she takes the elevator up to the 67th floor and walks the rest. On rainy days, she takes the elevator straight up to her floor. Why does she take the elevator to her floor on rainy days?
Mathematical Prowess
When asked to determine when clock hands form a right angle between 5:30 and 6:00, both QwQ and Gemma correctly calculated 5:43:38, with Mistral arriving at a close but incorrect answer.
Prompt: At what time between 5.30 and 6 will the hands of a clock be at right angles?
QwQ 32B: Correct answer after approximately 9.2 minutes of reasoning
Gemma 3 27B: Correct answer with minimal delay
Mistral Small: Correct answer
Deepseek r1: Correct answer after about 2.2 minutes
Gemma's efficient performance on mathematical reasoning was particularly impressive given its smaller parameter count.
Prompt: How many different ways can the letters of the word ‘MATHEMATICS’ be arranged so that the vowels always come together?
Practical Implications for Developers
For coding-intensive applications:
QwQ 32B emerges as the clear leader, sometimes even outperforming much larger models
Consider whether the Apache 2.0 license of QwQ aligns with your project requirements
For reasoning and general knowledge tasks:
QwQ shows the strongest overall performance, but Gemma offers competitive results with faster response times
Mistral lags behind the other two but still handles basic tasks competently
For multimodal applications:
Both Gemma and Mistral offer image input capabilities, providing a significant advantage for multimodal use cases
QwQ currently lacks this feature but compensates with superior text-based reasoning
License considerations:
QwQ and Mistral use the permissive Apache 2.0 license
Gemma uses Google's more restrictive custom license, which may impact certain commercial applications
Recent developments in compact AI models demonstrate a shift away from raw size as the primary determinant of performance. Models like QwQ 32B, Gemma 3 27B, and Mistral Small 3.1 24B showcase how intelligent architecture can deliver impressive capabilities in smaller packages. QwQ 32B stands out for its superior performance in coding and complex reasoning, while Gemma 3 27B offers an effective balance of speed and accuracy despite potential licensing limitations. Mistral Small 3.1 24B, though slightly behind its competitors, still provides a solid foundation for various applications.
Looking ahead, we can anticipate several key developments in this space. Architectural efficiency improvements will likely reduce parameter counts while maintaining or enhancing performance. We'll see more domain-specialized compact models optimized for specific fields like medicine, finance, and coding. On-device deployment will improve through optimized implementations for mobile and edge computing. Additionally, hybrid approaches that strategically combine local small models with selective API calls to larger models will become more prevalent, offering the best of both worlds in terms of performance, privacy, and cost-effectiveness.